gistリポジトリに一発で移動したい
Linuxコマンドの勉強の一貫としてシェルコマンドを考えてみた。
もっとスマートなやり方などがあれば教えていただきたいです🙇🏻♂️
gistをメモとして利用するにあたってリポジトリをghq経由で落としてきたが、編集のたびにいちいちディレクトリを移動するのが面倒...
gistのリポジトリ名にはgithubとは違いハッシュ値が振られてしまうので、ぱっと見でどのgistなのかわかりにくい...
ということで、"一発で"は誇張しすぎたかもしれないが、簡単にghq配下のgistリポジトリへ移動するシェルコマンドを考えた。
先に結論
このコマンドを実行することで、ghq配下のgistリポジトリにfuzzy検索を用いて移動することができる。
$ cd "$(ghq list -p | grep $(gh gist list | awk '{print $1, $2}' | fzf | awk '{print $1}'))"
やっていることとしては単純で、ghq list -pで出力されるghq配下のローカルリポジトリのフルパスを、あいまい検索で特定されたgistリポジトリのハッシュ値でgrepしている。
gistリポジトリへ移動するために大枠をcdで囲んでおり、個々のコマンドの出力には無駄な情報が含まれているので、awkコマンドで必要な情報だけに絞っている。
必要なもの
実際に使用するには以下ツールが必要。
ちなみにMacとzsh上で動作しているが、Linuxでもおそらく動くはず。
注意点
どのgistリポジトリにするのかという部分は、gistの説明文をfzfで曖昧に検索しているため、説明文が設定されていないと移動したい対象をハッシュ値で特定することになる。
また、gh gist listはリモートリポジトリ上の全てのgistが出力される。
そのためハッシュを特定したとしてもローカルリポジトリ(ディレクトリ)が存在しなければ移動できない。
本当はローカルに存在するgistだけを表示したいが、更にコマンドが複雑化しそうだったのと、必要であればローカルにghq経由でダウンロードできるので、一旦これでよしとしたい🥲
導入方法
コマンドを.zshrcなどの設定ファイルに記載する。
注意点にも書いたがローカルに存在しないgistリポジトリを選んでしまった場合のためにifで回避し、エイリアスでfunctionを呼び出している。
# ghq配下のリポジトリに移動する
function cd_ghq_on_fzf {
local dir="$(ghq list -p | grep $(gh gist list | awk '{print $1, $2}' | fzf | awk '{print $1}'))"
if [ -n "$dir" ]; then
cd "$dir"
else
echo "no such ghq directory"
fi
}
alias sd='cd_ghq_on_fzf'
あとはターミナル上でsdと叩けばおk
github上のリポジトリも検索対象にする
以下のコマンドを使用する。
上記のコマンドの結果にghq list -pでローカルにあるgistではなくgithub側のリポジトリの一覧を足しています。
$ cd "$(ghq list -p | grep $((gh gist list | awk '{print $1, $2}' ; ghq list -p | grep -v gist) | fzf | awk '{print $1}'))"
同じように設定ファイルに記載する。
# ghq配下のリポジトリに移動する
function cd_ghq_on_fzf {
local dir="$(ghq list -p | grep $((gh gist list | awk '{print $1, $2}' ; ghq list -p | grep -v gist) | fzf | awk '{print $1}'))"
if [ -n "$dir" ]; then
cd "$dir"
else
echo "no such ghq directory"
fi
}
alias sd='cd_ghq_on_fzf'
実際につかってみよう
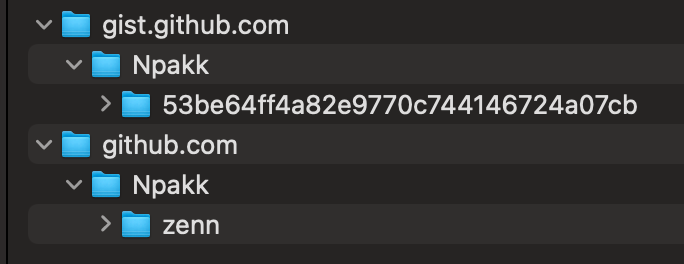
ふむふむ、github.comとgist.github.comというサービス名でディレクトリが別れていて、その下にユーザー名のディレクトリがありますね。
更にその下に各リポジトリを配置していますが、gistリポジトリは53be64ff4a82e9770c744146724a07cbというハッシュ値がディレクトリ(リポジトリ)名になってますね。
これでは、このリポジトリが指しているgistがどれなのかわからない...
そこで今回作ったsdを実行してみましょう。
最初はdotfilesというディレクトリにいます、覚えておいてください。

実行するとfzfが立ち上がり、github.comとgist.github.comの全てのリポジトリが表示されました!
でもまだ3件しかないのでいいけど、もし1000件あったらどうしよう...

安心してください!fzfはあいまい検索を提供してくれるのでぱっと思い浮かんだワードをターミナルに入力すれば、リポジトリを絞ってくれます!

あとはEnterを押すだけ。
dotfilesから対象のレポジトリに移動していることがわかりますね!
パット見ではどのgistなのかわからなかったこのディレクトリに、gistの説明文からハッシュ値を特定して移動してくることができました!

最後に
pecoを使ってghq配下のリポジトリへ移動する記事をいくつか見かけたが、fzfでかつgistを対象にしたものはなかったので作ってみた。
これでターミナル上でgistをメモツールとして使えるようになったので、積極的に活用したい。
作ってる最中に、gistをgithubリポジトリとして集約する方法を見つけて「あれ、こっちのやり方でやればgistリポジトリのハッシュ値も回避できて管理が楽じゃね」と思ったのは内緒の話。 Github Gist を1個のレポジトリでまとめて管理する ( git submodule を利用 )
あと都度更新するメモとしてはzennのスクラップでも可能なため、cli対応されたら100%乗り換えると思う🤣
Debianにlocateコマンドをインストール
新しいLinuxの教科書を読んでいて、locateコマンドの説明がでてきたが、自分の使っているVirtual Box上のDebianでは使えなかったので導入方法を調べてみた。
結論
apt-getをrootユーザーで実行する。
$ su #rootユーザに変更 $ apt-get install mlocate
補足
locateコマンドはmlocateパッケージに含まれているため、mlocateパッケージを導入する必要がある。
ソフトウェアをひとまとめにしたパッケージを管理するシステムは、Linuxのディストリビューション(正しくは派生形態)によって異なる。CentOSではyumというパッケージ管理システムが使われているらしいが、Debianではaptというものを使用する。
なお、シェルのコマンド上ではaptではなく、apt-getでパッケージをインストールしたり検索したりするので注意。
参考文献
eachの戻り値はレシーバそのもの
LeetCodeのtwo sumを解いてたら気になったのでメモ
Rubyのメソッドでは最後に評価された値を返すが、
以下のようなメソッドがあるとき(LeetCodeの回答としては未完成)、引数numsに[3,3] を渡すと戻り値がそのまま[3,3]だった。
どこからこの結果が算出されたのかわからなかったので調べてみた。
def two_sum(nums, target) nums.each.with_index do |n, index| value = target - n if nums[index+1...nums.size].include?(value) a = nums.index(value) return 'a' if index != a end end end p two_sum([2,7,11,15], 9) #=> "a" p two_sum([3,2,4], 6) #=> "a" p two_sum([3,3], 6) #=> [3,3]
結論
タイトルどおりだが、eachの戻り値だった。
eachは要素の数だけブロック内の処理を繰り返し実行するだけで、戻り値自体は指定がない限り、レシーバそのもの返すらしい。
上記のコード例でいえば、[3,3]が渡されたときだけ後置ifで真にならずreturnが実行されないため、eachのレシーバであるnumsそのものが戻り値となった。
以下をirbで実行するとわかりやすい。
明示的にbreak、もしくはメソッドに内包しreturnを行わない限りはレシーバそのものが返る。
nums = [1,2,3] nums.each do |n| end #=> [1,2,3] nums.each do |n| # 'foo'を返しループを抜ける break 'foo' end #=> 'foo'
参考文献
CSSのセレクタにタグは指定しないほうがいい
フィヨルドブートキャンプでmachidaさんからいただいたFBで、セレクタの指定によるブラウザの挙動を理解することが大事だとわかった。
結論
当初自分ではclassのセレクタにタグを併せて記載する指定をしていた。(classだけではなんの要素かわかりにくいと思ったため)
div.form-items {}
通常CSSのセレクタは左から右へ詳細度が高くなるように記載する。
しかし、ブラウザは右から左に解釈するため、上記CSSでは.form-itemsclassを理解した上で、そのclassに当てはまるdivタグをページから走査するみたい。
このため単純にclassのみをセレクタに書いた場合と比べて、パフォーマンスが悪くなる。
また、このようなタグをセレクタに記載すること自体、対象のHTMLに依存していて再利用性が低いという観点もありよろしくないとされている。
上記の再利用性が低いことやBEMなどの設計にセレクタの運用を合わせるためなどの理由で、最近はセレクタにタグやIDを使わずclassを指定するのが主流ということもわかった。
参考文献
Markdown基礎
以下は、自身がフィヨルドブートキャンプのカリキュラムで学んだ内容をメモしたものになります。
元の著者が表現したい内容を歪めている可能性もあるので、詳しくは参考文献をご確認ください。また、フィヨルドブートキャンプ 独自のコンテンツで学習したメモもあるので、気になった方はご参加いただければと思います。
参考文献
DARING FIREBALL by John Gruber
Markdown記法 チートシート
Markdownとは
Markdownとは
お手軽に文章構造を明示でき、読みやすさと書きやすさにこだわって開発された文章の書き方。
HTMLと合わせて使用することもできるが、HTMLで可能な表現を一部実現しているだけで、取って代わるようなものではない。あくまで文章表現の一種として限定されており、コンセプトとしては原文のままでも読みやすく、書きやすく、編集できることである。
HTMLと組み合わせられる
HTMLにあるdl要素(定義リスト)に相当するものがマークダウンにはないので、そのままHTMLを記載する。
このようにマークダウンにHTMLを直接記述することができる。
※HTMLのブロック要素の中ではマークダウンが有効にならない。例えば*(アスタリスク)による強調はHTMLで対応する必要がある。(インライン要素内では可能)
<dl> <dt>用語</dt> <dd>用語に対する説明</dd> <dl/>
↓
- 用語
- 用語に対する説明
リストの中にコードブロックを置く
コードブロックの行頭に8スペースか2タブ分が必要。
(原初のMarkdownにおいての仕様だが、そこから派生した記法を採用するアプリなどでは4つスペースでもいいこともある。もちろん、コードブロックなので前後に空行ではさむこと。)
1. FOO ```ruby puts "Hello, world!" ``` 2. BAR
↓
1. FOO
```ruby
puts "Hello, world!"
```
- BAR
※はてブではなぜかうまく表示されないみたい…詳しい方教えて下さい...
リンク
リンクは通常、下記のように[]()を組み合わせて記述する。
[Google](https://www.google.com/)
↓
Google
マウスホバー時にリンク先のタイトルを表示させることができる。
[Google](https://www.google.com/ "グーグル先生")
↓
Google
また、リンクにIDをつけてID経由で参照させることも可能。参照リンク
こうすることにより段落では文章の中身に集中することができ、読みやすく記載量を減らすことができる。
同様のリンクが多いほど、効果を発揮する。
[Google][id] [id]: https://www.google.com/ "グーグル先生"
↓
Google
自動リンク
URLやメールアドレスを<>で囲むだけで自動でリンクとして表示される。
<https://www.google.com/>
上記はMarkdownでは以下のように解釈されている。
<a href="https://www.google.com/">https://www.google.com/</a>
画像
画像はリンクに近いルールで記述する。
感嘆符のあとの[]には代替テキストを記載する。そのあとはマウスホバー時の表示テキストを任意で追加しても良い。

↓
参照リンクにも対応している。
![Alt Text][img_id] [img_id]: https://bit.ly/35lbZ3i "ピヨルド"
↓
HTMLの文書構造
以下は、自身がフィヨルドブートキャンプのカリキュラムで学んだ内容をメモしたものになります。
元の著者が表現したい内容を歪めている可能性もあるので、詳しくは参考文献をご確認ください。また、フィヨルドブートキャンプ 独自のコンテンツで学習したメモもあるので、気になった方はご参加いただければと思います。
参考文献
HTMLのアウトライン
アウトラインってなんだ
文章の階層構造のこと。
好きな食べ物 麺類 ラーメン 丼もの カツ丼
上記文章を階層構造にすると、
- 好きな食べ物
- 麺類
- ラーメン
- 丼もの
- カツ丼
このようなツリー構造をアウトラインという。HTMLの骨組みのようなイメージ。
アウトラインをHTMLで表現する
表現方法は2種類ある。 暗示的に表現するか、明示的に表現するか。
なお、直接階層構造によって読み手側の読むという体験が変化するわけではなく、あくまでブラウザ側が与えられた情報をどう解釈するかという話である。
しかしアウトラインがよく整理されたHTMLは、開発において扱いやすい構造になり、SEOなどシステム側にわかりやすく解釈してもらい、ひいてはHTMLを利用する読み手側にとってのメリットになりえるものである。
暗示的に表現
hタグである見出し要素を使うことで、ブラウザ側に構造を暗示(暗黙)し、ブラウザがアウトラインを勝手に解釈してくれる。
これはh1~6の数値(レベル)を使い分けることによって成り立つ。
<h1>好きな食べ物</h1> <h2>麺類</h2> <h3>ラーメン</h3> <h2>丼もの</h2> <h3>カツ丼</h3>
上記のようにhタグのhレベルによって、ブラウザがアウトラインを以下のように解釈する。
<h1>好きな食べ物</h1> <section> <h2>麺類</h2> <section> <h3>ラーメン</h3> </section> </section> <section> <h2>丼もの</h2> <section> <h3>カツ丼</h3> </section> </section>
明示的に表現
セクショニング・コンテンツであるarticle、section、asideといった要素で入れ子構造を明示的につくることで、アウトラインをブラウザに解釈させる。
<!-- 上に書いたHTMLと同じ --> <h1>好きな食べ物</h1> <section> <h2>麺類</h2> <section> <h3>ラーメン</h3> </section> </section> <section> <h2>丼もの</h2> <section> <h3>カツ丼</h3> </section> </section>
現在のHTML5の仕様ではセクショニング・コンテンツの中のhレベルはすべてh1でも書ける。
注意点
hレベルと重要度は無関係
hレベルと文章においての重要度は別の概念なので、重要度によってhレベルを上げ下げするとアウトラインを歪めてしまうので覚えておくこと。
暗示的な表現では最大レベルのhタグは一つでないといけない
暗示的にアウトラインを表現する場合、ブラウザの解釈に判断を委ねるわけだが、最大レベルとなるhタグが複数存在すると狙った通りのアウトラインにはならない。
<!-- bad --> <section> <h2>見出し★</h2> <h3>見出し</h3> <h2>見出し☆</h2> </section>
その他
HTML5では、bタグは太字を表すものではなくなった。
文章内のキーワードや製品名など、他と区別したいテキストに用いる。
参考URL - http://www.htmq.com/html5/b.shtml
HTML基礎
以下は、自身がフィヨルドブートキャンプのカリキュラムで学んだ内容をメモしたものになります。
元の著者が表現したい内容を歪めている可能性もあるので、詳しくは参考文献をご確認ください。また、フィヨルドブートキャンプ 独自のコンテンツで学習したメモもあるので、気になった方はご参加いただければと思います。
参考文献
HTMLってなに
Hyper Text Markup Language 「テキストを超越した文章に意味付けを行える文法」
なぜ生まれた
CERNに務めていたティム・バーナーズ・リーにより、1989年に発明された。
研究所において扱われる資料などは流動的に改変されるため、それらを常に最新に保つことは難しく、従来の本の分類分けのような管理方法では現状を把握することが困難であった。
そのため、組織やプロジェクトが変化していくのに合わせて自在に追加・拡張でき、コンピュータの機種に依存せず相互に情報交換が行なえ、階層構造で分類整理するのではなく文書自体を相互につなげる仕組み=WWWを考案した。
ハイパーテキストやリンクなどはこの仕組みの構成要素である。
HTMLを扱う際に大事なこと
これまでの普遍的な文書構造に従い、段落や強調などそれら文章の構成要素がもつ意味合いを表現し、読み手にとって読みやすいものであること。
文書を分析・管理している強力なシステムにとっても理解しやすいように、どこからどこまでがタイトルなのか、見出しはどこか、こういった要素を把握し、文章を構造として捉えること。
また、HTMLは文章の構造を記述することを目的としており、文字の形や色など見た目の情報をそこに混ぜると情報が不明確になってしまう。
HTMLに本来の役割以外の要素をもたせることは作者や読者に限らず、ハンディのある人にとっても不利益な結果になる。
情報を発信するということはコミュニケーションであり、誰にとっても使いやすく設計することが大事。
HTMLってなにでできてる
章、見出し、段落などの文書構造を構成する要素をタグと呼ばれる目印で示して表現している。
<p>Hello, world!</p>
具体的には<p>という開始タグと、</p>の終了タグ(閉じタグ)のペアで挟んで要素の内容を表現している。
HTMLにはこういった文書構造を示すために種類分けされた要素タイプがたくさん存在する。
またタグ同士を入れ子にすることにより親子関係をもたせることができ、子は親に属するという関係性を表現することができる。(親要素>子要素)
こうした親と子に枝分かれしたツリー構造をきちんと表現することが、これら文章を利用するシステムの利点を最大限に発揮するために極めて重要な概念である。
なお、要素同士は自由に親子関係になれるわけではなく、要素タイプごとに子要素になり得るものは決められており、 こうした関係を内容モデルと呼ぶ。文書型定義(DTD)というHTMLの文法書で定めらている。
HTMLは一番の親要素(ルート要素)にhtmlタグが存在し、大きくヘッド要素(head)とボディ要素(body)で構成されている。これらはそれぞれ1つの文書に1回しか使うことはできず、中に記載する情報も役割ごとに明確に分けられている。
<html> <head> <!-- 文書自身に関する情報を記載する(メタ情報) --> </head> <body> <!-- 見出し、段落など本文を構成する情報を記載する --> </body> </html>
ブロックとインライン
body要素の子要素となる要素タイプ群は、文書を構成する役割によって2つの種類に分けられる。 - ブロック要素 見出しや段落のように、それ自体が直接本文を構成する単位(ブロック)となる要素 - インライン要素 ブロックの一部分に対してそれを装飾するような役割をもつ要素
インライン要素内にブロック要素を置かないなどHTMLを構成する上で大事な原則である。
CSSで見た目を装飾する際に意図した挙動にならない場合などの問題が発生した際も、ブロックとインラインの概念は重要。
よいHTMLとは
WWWを使うユーザーには見る人聞く人、はたまた世界中のページを収集するロボットまで様々なユーザーがいる。
これらすべてのユーザーがハッピーになれるように書かれたHTMLのこと。
タイトルちゃんとつけよう
読み手だけでなくて作者自身にもタイトルは有用である。
本の背表紙のように一瞬でその文章に何が書かれているか、簡潔で具体的なタイトルをつけることを意識する。
altテキストには画像が示す意味を記載する
なんの画像があるのかということを書いても、音声ソフトで読み上げたときに意味が通じない。
その画像が示している意味を記載しよう。
アンカーには意味のある文を
リンクのための文章にするのではなく、そのまま読んでも意味が通じるようにアンカーテキストを配置すること。
ナビゲーションを活用する
Web文書は書物に比べて2次元情報に配置されているため、利用者は全体を俯瞰しにくく迷子になりやすい。
今どこにいるのか、次はなにか、利用者が迷子にならないようナビゲートし、またそれらに関する窓口を適切に用意する。
文書や作者に関する情報を示す
いつどこから文書がリンクされるか予測することは不可能。
作者の意図に反して文書が利用されることもある。
すべての文書に作者がだれであるかをたどれる情報を用意し、address要素に連絡先やメールアドレスを記載するなど作者自身が誰であるかを明示すること。
自分の情報を提供し、知らないことはリンクする
インターネットは分業の世界。自分より詳しい情報源があれば、そこへのリンクを提供する。
ユーザー全体で特定のトピックや情報を作り上げる意識を持つこと。
他者ではなく自分の情報を示すこと。
わるいHTMLとは
ユーザーの視点に配慮されていないHTMLのこと。
無意味な画像の多用
画像でなければ伝えられない情報に対してのみ、画像を用いること。
ページパフォーマンスや通信費などに影響するため、思い描いたデザイン通りにしようとした画像の乱用は避ける。
(大きな画像1枚より小さい画像の複数枚のほうがページ表示の時間がかかる。)
ページ全体をテーブルで囲む
テーブルは範囲全てがブラウザにダウンロードされないと描画されないため、ページ全体を囲むとしばらくの間ユーザーは空白を見つめることになる。
音声読み上げソフトで利用しているユーザーにとっては致命的。
描画された最初の部分を読みながら、後続をダウンロードできるのだから、ユーザーを置き去りにしないこと。
選択の自由を奪う
Webは好きなときに好きなページを読むことができる自由度の高さがあり、従来のメディアでは不可能だった新しい世界を生み出した。
ナビゲーションでユーザーの選択肢を狭めて進む手段を与えないようにしたり、リンクを新しいウィンドウで常に開く、画面サイズを固定する、最初に大きなアニメーションを魅せるなど、自由度を下げ利用者の自由を奪わないこと。
作者の考えた使い方を強制しないこと。
特定の環境に依存する
日々進化するHTMLの新機能は魅力的だが、その機能を持たないものを排除するべきではない。
だれもが利用できる状態を目指すこと。
ちゃらちゃら動く物が多い
画面上でアニメーションやGIFなどを多用しないこと。
本来の伝えたい情報、注目すべき内容を重視すること。利用者にとっては集中できないだけでなく、読解不能もありうる。
どうしても必要な場合でも、何らかの機能でオフにできるなど、利用者に自由度を与えること。